GrafanaでS3に置いてあるログファイルを参照する
きっかけは以下のツイートを見かけたことでした。
Grafana を立てるだけで、S3 にログ保存しておけば、好きなだけグラフが作れる時代が来てしまった。なんということだ。 https://t.co/uuYgm8dLIr
— V (@voluntas) 2025年2月13日
なにこれ良さそう。GrafanaもDuckDBも全然知らんけど。
ということで試してみました。
キーアイテム
grafana-duckdb-datasourceというGrafanaプラグインを使用します。
github.com
前提
- Grafana Version:
v11.6.0-82874 (e5b49a406f) - Container Image:
grafana/grafana-enterprise:main-ubuntu - Container OS:
Ubuntu 22.04.5 LTS - Container CPU Architecture:
ARM64 - Container Runtime:
podman version 5.3.1 - Host OS:
M1 Mac
M1 MacでPodmanでGrafanaコンテナを使いました。でもたぶん、WindowsとかDockerとかでもだいたい動くんじゃないかと思います。試してはいませんが。
環境構築
grafana-duckdb-datasourceプラグインの準備に関しては公式の手順に従います。
GitHub - motherduckdb/grafana-duckdb-datasource
ただし今回はGrafanaコンテナを使うので、それを加味した手順を以下に記します。
Grafanaの設定ファイルを用意
grafana-duckdb-datasourceのインストール手順にある通り、未署名のプラグインをGrafanaに登録するには、そういうのを許可するための記述を設定ファイルに追加する必要があるそうです。ちなみに、Grafana公式の設定リファレンスはこちら。
Configure Grafana | Grafana documentation
今回はGrafanaコンテナを使うので、コンテナから設定ファイルをホスト側にコピーしてきてそれを編集します。
まずGrafanaコンテナから設定ファイル(grafana.ini)を取得します。
podman run -d --rm --name=grafana grafana/grafana-enterprise:main-ubuntu podman cp grafana:/etc/grafana/grafana.ini ./conf/
コピーした設定ファイルの配置先をここでは./conf/としていますが、どこでも構いません。
コピーしたら、Grafanaコンテナは停止します。ここでは設定ファイルがほしくて起動しただけなので。--rmをつけているので、停止したら削除までされます。後でオプションを増やしてまたちゃんと起動します。
podman stop grafana
コピーしてきたgrafana.ini を編集します。
allow_loading_unsigned_pluginsという項目が設定ファイルにすでにあるはずなので、許可したいプラグインであるmotherduck-duckdb-datasourceを右辺に書きます。
- Before
;allow_loading_unsigned_plugins =
- After
allow_loading_unsigned_plugins = motherduck-duckdb-datasource
項目の行頭にセミコロン;がついている場合、それはコメントアウト記号なので除去します。
motherduck-duckdb-datasourceプラグインを用意
公式の手順にある通り、motherduck-duckdb-datasourceプラグインをダウンロードしてきてunzipコマンドで展開します。
ここではplugins/motherduck-duckdb-datasourceに展開したものとします。
ls plugins/motherduck-duckdb-datasource
バージョン次第で内容が変わるかもしれませんが、motherduck-duckdb-datasourceフォルダをlsすると概ね以下のような内容になっているはずです。
CHANGELOG.md gpx_duckdb_datasource_darwin_arm64* grafana-lokiexplore-app/ module.js.LICENSE.txt LICENSE gpx_duckdb_datasource_linux_amd64* grafana-pyroscope-app/ module.js.map README.md gpx_duckdb_datasource_linux_arm64* img/ plugin.json go_plugin_build_manifest gpx_duckdb_datasource_windows_amd64.exe* module.js
Grafanaコンテナを起動
さて準備が整いました。Grafanaコンテナを起動しましょう。
podman run -d --user root --rm -p 3000:3000 \ -v ./conf/grafana.ini:/etc/grafana/grafana.ini \ -v ./plugins:/var/lib/grafana/plugins \ -e "GF_DEFAULT_APP_MODE=development" \ --name=grafana grafana/grafana-enterprise:main-ubuntu
以下、簡単な説明です。
--user root: ルートユーザを使っています。motherduck-duckdb-datasourceプラグインがコンテナ内で動作するために必要な権限を与えるためです。-p 3000:3000: 3000番ポートを使っています。すでに他のアプリで使っている場合などは適宜変更してください。-v ./conf/grafana.ini:/etc/grafana/grafana.ini: 編集した設定ファイルコンテナにバインドマウントしています。-v ./plugins:/var/lib/grafana/plugins:motherduck-duckdb-datasourceプラグインを、Grafanaコンテナのプラグインディレクトリ配下にバインドマウントしています。-e "GF_DEFAULT_APP_MODE=development": なんか開発モードみたいな設定にしないといけない?っぽいので、環境変数を設定しています。grafana/grafana-enterprise:main-ubuntu: Grafana公式のコンテナイメージを使います。Alpine Linuxのイメージもあるようなのですが、それだとうまくいかないのでUbuntuベースのイメージを使います。
motherduck-duckdb-datasourceプラグインの確認
Grafanaが立ち上がったら、motherduck-duckdb-datasourceプラグインがちゃんと使えそうか確認します。
http://localhost:3000 でGrafanaにアクセスします。

初期設定のユーザ/パスワードはどちらもadminなので、それを入力してLog inボタンを押します。
パスワード設定画面が表示されますが、一時的な用途ならスキップしても構いません。もちろんきっちり設定しても構いません。
ログインしたら、サイドメニューから Administration > Plugins and data > Plugins に進みます。
進んだら、検索欄でduckとかで検索しましょう。 Duckdb-Datasourceというのが出てきたらOKです。

motherduck-duckdb-datasourceプラグインでS3のログファイルを参照する
ではプラグインを使ってS3のログファイルを参照してみましょう。
(ここまでもそうですが)ここからはDuckDBのドキュメントが参考になります。 参照できるデータファイルのフォーマットや参照する方法も、DuckDBの以下のドキュメントに従います。 duckdb.org
ログファイルはなんでも良いのですが、私はSpring Bootで適当に出力したJSONL形式のログを使いました。 少し前に以下の記事に掲載されているスライドを見て興味が湧き、試したときのログファイルがちょうどあったのでした。
ということでログファイルをS3の適当なバケットにアップロードします。 なおこのとき、バケットのパブリックアクセス設定を緩める必要はありません。
DuckDBはS3 APIをサポートしていて、S3へのアクセスにはAWSのアクセスキーを利用するためです。 duckdb.org
アクセスキーといえば、AWS CLIとかでお馴染みの、AWS APIを利用するのに必要なあれですね。
ということであれを用意しましょう。用意したら、それをプラグインに登録しましょう。
さきほどのPlugin一覧で表示されたDuckdb-Datasourceをクリックします。
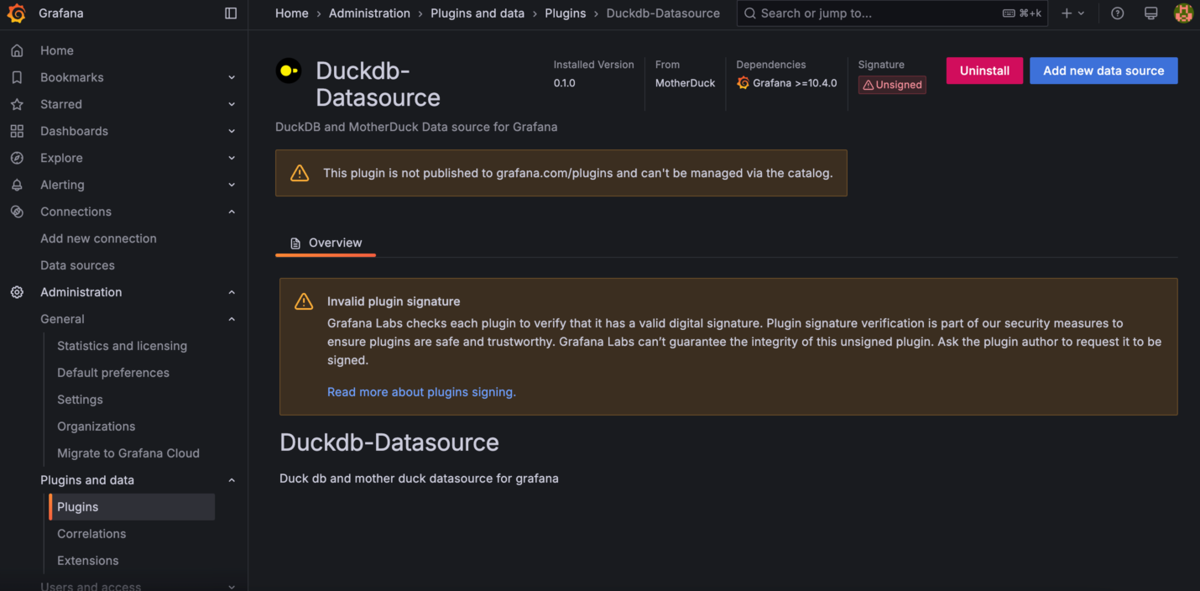
警告が大きく出ていますが承知の上です。構わず(?)右上のAdd new data sourceをクリックします。
すると、motherduck-duckdb-datasourceのデータソース設定画面が表示されます。なお、サイドメニューのData sourceからmotherduck-duckdb-datasourceを検索しても同じ画面に辿りつきます。
設定項目の説明はプラグインの公式にあります。
GitHub - motherduckdb/grafana-duckdb-datasource
Path: DuckDBのファイルのパスを記入する欄らしいです。未設定の場合、インメモリモードになります。S3のファイルを読むにはこのインメモリモードで問題ないので未設定のままとします。MotherDuck Token: MotherDuck APIとやらを使う場合のトークンらしいです。今回は使わないのでノータッチ。(そのうち調べたい)
その他に、設定画面にはInit SQLという項目もあります。
ここには、データソースとのコネクションが確立された際に実行される初期化用のSQLを記述できます。
で、DuckDBからS3へのアクセスにはアクセスキーが必要なので、この初期化SQLでDuckDBにアクセスキーを登録します。
公式(前掲したS3 API Supportのページ)を見ると認証チェーン(認証情報の登録先候補を順に走査して使えるやつがあれば使うやつ)なんかもあるみたいですが、今回は1つの認証情報をDuckDBに登録する方法を使います。
ということで、Init SQLの入力欄には次のようにSQLを入力します。
CREATE SECRET secret1 ( TYPE S3, KEY_ID 'アクセスキー', SECRET 'シークレットアクセスキー', REGION 'リージョン。東京ならap-northeast-1' );
KEY_ID, SECRET, REGIONには例のあれを指定します。
記述したら、Save & testを押します。

SQLや登録情報に誤りがなければ、以下のようにData source is workingという感じのメッセージが表示されます。

これで、認証情報の登録が完了しました。 ではいよいよS3のログファイルを参照してみましょう。
サイドメニューのExplore を選択し、画面上部のプルダウンでmotherduck-duckdb-datasourceを選択します。
次に、画面上部右側のBuilder/CodeのトグルでCodeを選択します。するとクエリの入力欄が出てくるので、次のように入力します。
SELECT * FROM read_json_auto('s3://heraction-log-temp/boot.log');
s3://~の部分には、対象のログのS3 URIを指定します。できたら、入力欄の右上のRun queryを押します。
するとどうでしょう、S3に置いてあるログファイルの中身が表示されたではありませんか!

SELECT句でカラムを指定することも可能です。なおここのカラムとは、JSONL形式におけるJSONデータ各行に含まれる、各プロパティのキー名称です。
ただし上記のように、カラム名(キー名称)にドット.が含まれている場合、二重引用符で囲む必要があります。

WHEREもORDER BYも書けちゃいます。

この辺はもう完全にDuckDBの領域っぽいので、DuckDBのドキュメントに書かれてあることはだいたい可能なんじゃないかなと思います。たぶん。 ちなみに、S3じゃなくてローカルのファイルを読み込むこともできます。ただしもちろん、 Grafanaをコンテナ起動した場合はコンテナのファイルシステムがローカルになる(この表現合ってる…?)ので、ホスト側のファイルを読み込ませるにはマウントしたりする必要があります。
所感
ここまでたどり着くのに苦労しました。やたら遠回りしたし、初めてOSSにIssueを上げた後でクローズ済みのIssueで似たようなのがあることに気づいたりして。 ただ、一度構築できてしまえば手触りはかなり良い感じです。 機能不足を感じる部分もありますが、まだまだこれからも改善されていくことを期待しています。Issue上げてOSSコントリビュートデビューしたことだし、自分でそういうのを提案していくのもありかも。 でもその前に、GrafanaやDuckDBの学習過程をかなりすっ飛ばしているのでそっちをやらねば。
あと今回は雑に13KB程度のログファイルを読み込んだのですが、ログファイルが大きくなったときにどの程度メモリを食うのかは気になります。 まあそんなに大きくならないようにログローテーションを組みなさい、という話ではありますが。
まとめ
grafana-duckdb-datasourceを使ってS3のログファイルを参照する方法をご紹介しました。
今回は単に動かしてみたかっただけなので雑にバインドマウントしたりしましたが、真面目に運用するのであれば細部は適宜検討する必要があるでしょう。